Diffusion LLMs Arrive: Mercury 2 Shatters AI Speed Barriers
Inception Labs has unveiled Mercury 2, the world's first Diffusion Large Language Model (DLM) capable of reasoning. This new architecture significantly outperforms traditional Transformer models in speed and accuracy, potentially reducing AI hallucinations and enabling near-instantaneous applications.

Mercury 2 Ushers in New Era of AI Reasoning and Speed
A groundbreaking development in artificial intelligence has emerged with the unveiling of Mercury 2, a novel AI model from Inception Labs that promises to redefine the landscape of language models. Dubbed the world’s first Diffusion Large Language Model (DLM) capable of genuine reasoning, Mercury 2 represents a significant departure from the dominant Transformer architecture, potentially marking a key moment in AI akin to the Transformer’s own invention.
Understanding the Diffusion Leap: Beyond Transformers
For years, the AI community has largely relied on the Transformer architecture, popularized by the 2017 paper “Attention Is All You Need.” Models like GPT-4, Claude, and Gemini operate on this principle, generating text token by token in a sequential, auto-regressive manner. While effective, this approach faces inherent limitations, most notably error compounding.
If an early token is suboptimal, subsequent tokens build upon that error, leading to potential drifts in accuracy and increased hallucinations, especially in longer outputs. Esteemed AI researcher Yann LeCun has long pointed out that this auto-regressive nature hinders the planning and reasoning capabilities of current LLMs.
Diffusion models, on the other hand, have already revolutionized image generation with tools like Midjourney and Stable Diffusion. These models start with random noise and iteratively refine it through multiple steps to produce a coherent image. Inception Labs has now successfully adapted this paradigm for text generation, creating Mercury 2.
Instead of generating word by word, Mercury 2 begins with a noisy representation of the entire answer and progressively refines it across multiple passes. This iterative self-correction mechanism allows the model to revisit and improve its output, much like an editor polishing a manuscript.
Mercury 2: A Speed and Reasoning Powerhouse
The implications of this diffusion approach are profound. Mercury 2 demonstrates a remarkable leap in both speed and reasoning capabilities.
In direct comparisons, Mercury 2 significantly outperforms existing models, including Anthropic’s Claude 4.5 Haiku and OpenAI’s GPT-4 Turbo variants, often achieving speeds five to ten times faster for tasks of comparable complexity. This speed is attributed to the parallel processing nature of diffusion models, allowing Mercury 2 to output over 1,000 tokens per second.
Beyond raw speed, Mercury 2’s ability to reason and self-correct during generation addresses the long-standing issue of hallucinations. By refining its entire output, the model can identify and rectify inaccuracies, leading to more reliable and coherent responses. This capability is crucial for applications requiring high levels of accuracy and planning.
Key Capabilities and Benchmarks
Mercury 2’s prowess extends across various domains:
- Code Generation: The model can write entire functions and refine them iteratively, demonstrating a speed advantage over traditional models.
- Real-time Voice Interaction: It can process queries and generate coherent, refined responses almost instantaneously, improving user experience in conversational AI.
- AI Agents: Mercury 2 supports tool use, structured outputs, and retrieval-augmented generation (RAG) with a substantial 128k context window, enabling complex agentic behaviors and integration with external APIs.
In benchmark tests, Mercury 2 has shown competitive, and in some cases superior, performance against leading models on tasks such as scientific questions (GPQA Diamond) and mathematical problems (GSM8K, MATH). Its ability to handle long documents and integrate with existing systems via an OpenAI-compatible API further enhances its practical utility.
Why This Matters: The Real-World Impact
The advent of Mercury 2 and DLMs signals a potential paradigm shift with far-reaching consequences:
- Reduced Hallucinations: The self-correction mechanism inherent in diffusion models promises more trustworthy AI outputs.
- Enhanced Reasoning: The ability to plan and revise entire outputs unlocks more sophisticated reasoning capabilities, moving beyond linear generation.
- Near-Instantaneous AI Applications: The dramatic increase in speed and potential reduction in computational cost could make previously unviable AI applications, such as real-time voice agents, seamless translation services, and highly responsive co-pilots, a reality.
- Democratized Development: With an OpenAI-compatible API and competitive pricing (e.g., $0.25 per million input tokens, $0.75 per million output tokens), developers can more easily integrate Mercury 2 into their applications.
Building with Mercury 2
Inception Labs provides direct access to Mercury 2 via their API at chat.inceptionlabs.ai. For developers looking to integrate the model, it’s available through platforms like OpenRouter, which supports its high throughput and 128k context window. The OpenAI compatibility of its API simplifies migration, requiring minimal code changes to leverage Mercury 2’s advanced capabilities.
Demonstrations showcase Mercury 2’s ability to generate complex code, such as a functional Tetris clone with an upward-falling mechanic, in mere seconds. Further examples include building a galaxy simulator using vanilla JavaScript, highlighting the model’s capacity for rapid and accurate code generation.
The Future of Diffusion LLMs
Mercury 2’s emergence suggests that diffusion models are poised to become the next major advancement in AI, much like Transformers did a few years ago. While Transformers took approximately five and a half years from architectural invention to mainstream adoption, the rapid development and deployment of DLMs like Mercury 2 indicate a potentially faster evolutionary path. Inception Labs’ work not only introduces a powerful new model but also validates a fundamentally different architectural approach, enabling a new generation of faster, more capable, and more reliable AI systems.
Source: Build Anything with Mercury 2, Here’s How (YouTube)
Related Articles


Iran’s Digital Barrage: How Social Media Targets Trump
Iranian social media accounts are using AI and rapid content creation to mock Donald Trump and his allies. They employ satire and direct accusations, turning Trump's own tactics against him. This digital campaign highlights the growing role of social media in international influence operations.
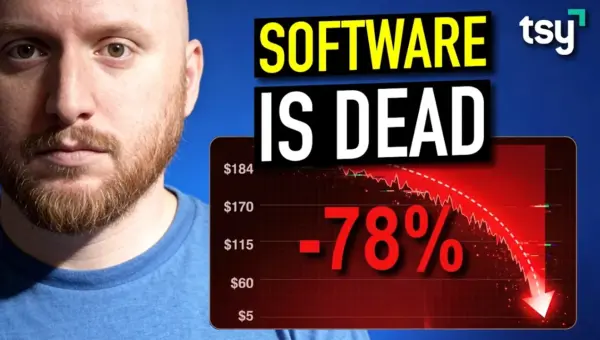
AI Unleashes New Shockwaves Across Software Sector
New AI models like Claude are rapidly disrupting the software industry, challenging traditional business models and impacting stock valuations. Investors are shifting focus from software companies to the underlying AI infrastructure and cloud services powering these advancements. The trend suggests a significant revaluation of software assets as AI takes over human-driven workflows.

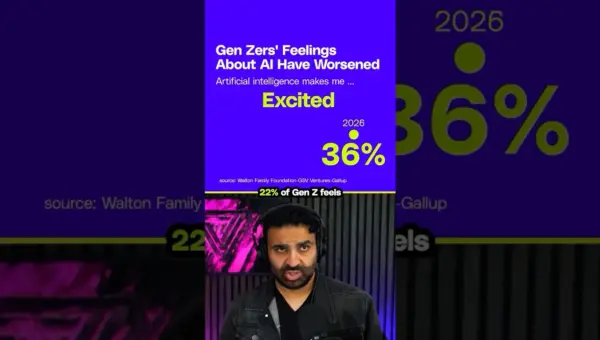
Gen Z’s AI Enthusiasm Dips Sharply
New data shows Gen Z's excitement for AI has sharply declined, with anxiety and anger on the rise. This contrasts with AI experts' high optimism about the technology's impact on jobs. Bridging this perception gap is crucial for AI's future.