AI Models Learn by Embracing Digital ‘Suffering’
Artificial intelligence models are learning to solve complex problems by experiencing digital 'pain' through reinforcement learning. This method involves intentional failure and negative feedback, pushing AI to adapt and improve. It mirrors human learning processes of trial, error, and delayed reward.

AI Models Learn Through Digital Pain
Artificial intelligence models are achieving new levels of success, but the path to this success involves a process that mirrors human suffering. This might sound strange, but AI developers have found that making models experience digital ‘pain’ helps them learn faster and better. It’s like teaching a child by letting them make mistakes and learn from them, but on a massive scale.
This approach involves creating situations where the AI model is intentionally given tasks it cannot immediately solve. These difficult tasks are designed to push the AI beyond its current abilities. When the AI fails, it receives a signal that it did not perform well, similar to how humans feel disappointment or frustration.
The Concept of ‘Suffering’ in AI
In the world of AI, this digital ‘suffering’ is often implemented through what developers call reinforcement learning. This is a technique where an AI agent learns to make decisions by performing actions in an environment to achieve some goal. The agent receives rewards for good actions and penalties for bad ones.
Think of it like training a dog. You give the dog a treat (a reward) when it sits on command.
If the dog chews your shoes, it might get a verbal reprimand (a penalty). Over time, the dog learns which actions lead to treats and which lead to scolding.
How AI Models Experience ‘Pain’
For AI, these penalties are not emotional but are numerical. When an AI model makes a mistake or fails to complete a task efficiently, its internal scores are lowered. This negative feedback guides the AI to adjust its strategy and try different approaches.
Developers set up complex challenges where success is not guaranteed. The AI explores many different paths, often failing repeatedly.
Each failure provides valuable data, showing the AI what not to do. This iterative process of trial, error, and adjustment is key to its development.
The Role of ‘Uncertainty’ and ‘Delay’
Just as in human learning, AI development involves uncertainty and delay. The AI doesn’t know the best way to solve a problem from the start. It must explore possibilities, and there’s no guarantee it will find the optimal solution quickly.
This uncertainty means the AI might take many steps, or a long time, before it achieves a positive outcome. The delay between an action and its eventual reward or penalty can be significant. This mirrors how humans often have to wait for results after putting in effort.
Why This Matters
This method of learning through digital hardship is proving incredibly effective. It allows AI models to tackle much more complex problems than before. These include advanced tasks in areas like robotics, game playing, and scientific research.
By embracing these digital challenges, AI systems can develop more sophisticated decision-making skills. They become more adaptable and better at finding novel solutions. This means AI can be used to solve bigger, real-world problems more efficiently.
Specific Examples and Future Steps
Companies like DeepMind, a Google AI lab, have used similar reinforcement learning techniques to train AI to play complex games like Go and chess at superhuman levels. OpenAI has also employed these methods in developing advanced language models.
While specific pricing for these advanced training methods isn’t public, the underlying research is often published. Developers continue to refine these techniques, aiming to make AI learning even more efficient. The next steps involve scaling these methods to even larger and more complex AI systems.
Source: Most successful man of all time (YouTube)
Related Articles

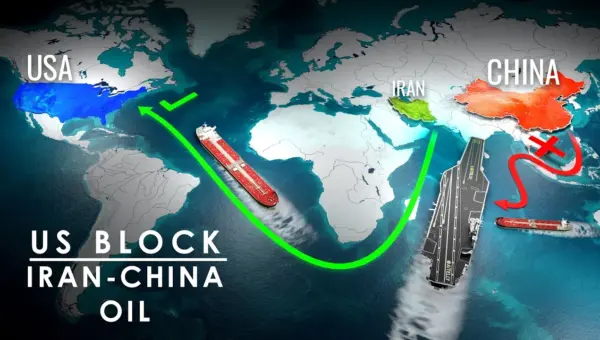
AI Tracks Oil Tankers, Aiding US Strategy Against China
The US is employing advanced AI to track oil tankers, aiming to counter China's reliance on foreign oil. This strategy uses AI to monitor ships, identify sanctioned cargo, and influence global energy markets by disrupting supply chains. The goal is to assert energy dominance and shape international economic outcomes.
AI Jesus Offers Paid Spiritual Guidance for $1.99/Minute
A US tech startup now offers AI Jesus, a paid service providing spiritual guidance for $1.99 per minute. Trained on the Bible and sermons, the AI aims to offer comfort and mentorship. This service taps into a booming $2 billion market for AI-driven spiritual wellness tools, but raises concerns about data privacy and misinformation.


AI Spending Frenzy Faces Reality Check: Anthropic Leads
AI's massive spending boom faces scrutiny as Anthropic CEO Dario Amodei highlights concerns about overestimated demand. Many companies are burning through AI budgets faster than expected, with some even encouraging token usage over actual productivity. Anthropic is shifting to per-token billing, moving away from unsustainable flat-rate plans.