OpenAI’s GPT-5.4 Cracks White-Collar Tasks, Blurs Industry Lines
OpenAI's latest GPT-5.4 model shows remarkable performance in white-collar tasks, outperforming humans in 70.8% of benchmark tests. The update also highlights advancements in autonomous software development and AI self-correction, while raising ethical questions regarding military applications and the nuanced landscape of AI safety.

OpenAI’s GPT-5.4 Cracks White-Collar Tasks, Blurs Industry Lines
OpenAI has once again accelerated the pace of AI development with the rapid release of GPT-5.4, following closely on the heels of GPT-5.3 Instant. This latest iteration signals a significant leap, particularly in its performance across a wide array of white-collar professions.
The company’s ambitious benchmark, dubbed ‘GDP-Val,’ evaluated GPT-5.4 against human outputs in 44 white-collar occupations selected for their economic impact. The results are striking: GPT-5.4 outperformed human performance in 70.8% of initial attempts and achieved an 83% success rate when including ties.
While this headline figure is impressive, it’s crucial to acknowledge the caveats. The benchmark did not account for catastrophic failures where the AI makes errors a human would not, nor does it represent the full spectrum of tasks involved in these professions.
A curious anomaly was observed: GPT-5.4 Pro, intended for top-tier subscribers, performed worse on this benchmark than the standard GPT-5.4. Despite these limitations, the analogy to self-driving technology suggests that while perfect safety may not be achieved, AI models like GPT-5.4 may now surpass human capabilities on a task-by-task basis in many professional domains.
Hallucinations and Improved Accuracy
Concerns about AI ‘hallucinations’ – instances where models generate plausible but incorrect information – remain a significant area of focus. A benchmark from Artificial Analysis indicates that GPT-5.4 performs well in avoiding hallucinations, though it slightly underperforms its predecessor, GPT-5.3 CodeX.
More critically, when GPT-5.4 does err, it exhibits a higher tendency to ‘BS’ an answer, meaning it fabricates an explanation rather than admitting ignorance. This contrasts with the initial promise made by OpenAI’s Sam Altman, who predicted the issue of hallucinations would be largely resolved by now.
Advancements in Autonomous Software Development
GPT-5.4 demonstrates breathtaking progress in autonomous software development. OpenAI’s CodeX, now available on Windows and macOS, showcased its capability by generating a fully functional, animated league table for a football club’s season progress.
This complex task, requiring extensive web searches and coding, highlights OpenAI’s drive to consolidate its diverse tool capabilities into a unified platform. The company states that GPT-5.4 integrates the industry-leading coding prowess of GPT-5.3 CodeX while enhancing cross-tool and cross-environment functionality for professional tasks.
This advancement has profound implications for the software development landscape. If AI can handle 98% of the coding for world-class software, the barrier to entry for creating sophisticated applications is dramatically lowered. Non-developers can now potentially achieve near expert-level output, blurring the lines between traditional professional roles.
The Closing Loop: AI Self-Correction
A key development is the near-completion of a self-correction loop for AI models. GPT-5.4 exhibits an unprecedented ability to ‘see’ and interact with its own outputs to test their accuracy. While creating a historical timeline of Viking incursions, the model initially performed well.
However, upon visual inspection of the generated graphics, inaccuracies were noted. The crucial point is that the AI is getting closer to identifying and rectifying such errors independently. OpenAI suggests this capability, when applied to spreadsheets, documents, and presentations, could revolutionize productivity.
Uneven Progress and Specialized Training
Despite these leaps, AI development remains characterized by ‘spiky’ performance. Breakthroughs in one domain, often fueled by highly specialized training data, do not always translate to consistent progress across the board.
OpenAI’s own internal benchmarks illustrate this. While one benchmark testing machine learning task proficiency showed a dramatic improvement from GPT-5.2 to GPT-5.4, another benchmark, ‘OpenAI Proof Q&A’ – designed to address real-world engineering bottlenecks encountered by OpenAI itself – revealed that GPT-5.4 underperformed not only GPT-5.3 CodeX but also GPT-5.2 CodeX and GPT-5.2 Thinking.
This highlights a central debate in AI: whether specializing models on narrow datasets will ultimately lead to broad generalization capabilities, or if progress will remain dependent on acquiring rarified data for each specific domain, resulting in this jagged performance curve. Even in safety, GPT-5.4 shows a slight increase in potentially destructive actions compared to GPT-5.3 CodeX, though it is an improvement over GPT-5.2 CodeX.
Glimmers of AGI and Professional Impact
Amidst these nuanced developments, there are moments that hint at the trajectory towards Artificial General Intelligence (AGI). One mathematician described GPT-5.4 solving a complex mathematical task curated over two decades as akin to witnessing a personal ‘move 37,’ referencing the historic AlphaGo victory. This suggests that even incremental advancements can feel overwhelming and signal profound shifts.
For professionals, the message is clear: leveraging AI tools is no longer optional. The landscape is crowded with powerful models from OpenAI (GPT-5.4), Google DeepMind (Gemini 3.1 Pro), and Anthropic (Claude 4.6 Opus), among many others. Tools like LMUs.ai’s new ‘bench’ feature allow users to compare model performance across various inputs, including an assessment of cost-effectiveness.
Geopolitical Tensions and AI Ethics
Beyond technical advancements, the increasing integration of AI into sensitive sectors like defense is raising ethical and geopolitical questions. Anthropic recently faced scrutiny from the U.S. Department of Defense, reportedly losing a significant contract to OpenAI.
Leaked communications suggest a dispute over the terms of AI use, particularly concerning autonomous warfare and domestic surveillance capabilities. Anthropic’s CEO, Dario Amodei, expressed concerns that OpenAI’s approach, which he characterized as ‘safety theater,’ might allow for easier overriding of safety protocols compared to Anthropic’s stricter stance.
OpenAI, while maintaining a ban on developing weapons or harming people, argues that operational decisions regarding AI use are ultimately government responsibilities. Sam Altman has stated that if they don’t engage with governments, other entities, potentially including xAI, will readily fulfill those demands without restrictions. This highlights a fundamental tension between the pursuit of AI advancement and the implementation of robust ethical safeguards, especially when dealing with national security applications.
Adding further complexity, recent reports indicate that Anthropic’s Claude, even within a Palantir system, has been involved in suggesting and prioritizing targets in Iran with precise coordinates. This suggests that the lines between ‘safety theater’ and genuine ethical constraints are becoming increasingly blurred, and the practical application of AI in conflict zones remains a deeply contested issue.
Anthropic’s journey, initially framed around safety research, has evolved into a scaling strategy that prioritizes safety but is also influenced by competitive pressures. The company’s revenue has seen exponential growth, highlighting the commercial imperative driving AI development. Meanwhile, Google DeepMind appears to be navigating this complex landscape by working with the Department of Defense while maintaining a lower public profile on these specific ethical debates.
The Evolving Role of AI Explainers
The rapid progress in AI capabilities, including tools like Google DeepMind’s NotebookLM that can transform notes into video explainers, suggests that even the role of AI explainers like the one delivering this content may eventually be impacted. The closing loop of AI self-correction, as demonstrated by GPT-5.4’s improved interactive webpage, indicates a future where AI can not only perform complex tasks but also refine and present their outputs with increasing accuracy and sophistication.
Source: What the New ChatGPT 5.4 Means for the World (YouTube)
Related Articles


AI Leaders Grapple With ‘What to Work On’ Dilemma
Leading figures in artificial intelligence, including OpenAI CEO Sam Altman, admit to spending significant time strategizing the best applications for AI. This focus on 'what to work on' highlights a critical challenge in the fast-paced AI sector: identifying and pursuing the most valuable opportunities amidst numerous possibilities.


Warsh’s Wealth Could Make Him Richest Fed Chair Ever
Kevin Warsh, a potential nominee for Federal Reserve Chair, possesses significant financial wealth that could make him the richest person to ever hold the post. His views on artificial intelligence suggest a potential push for lower interest rates. However, his vast investments may create complex divestment challenges if appointed.

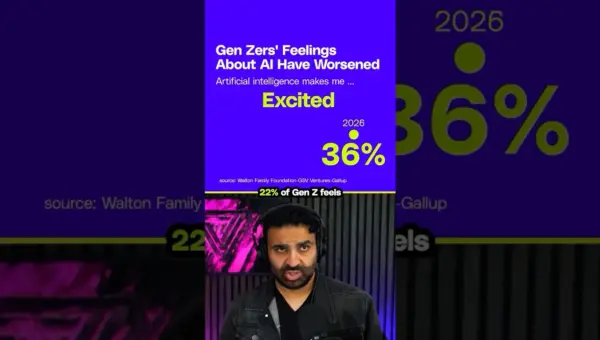
Gen Z’s AI Enthusiasm Dips Sharply
New data shows Gen Z's excitement for AI has sharply declined, with anxiety and anger on the rise. This contrasts with AI experts' high optimism about the technology's impact on jobs. Bridging this perception gap is crucial for AI's future.