Google’s TurboQuant Slashes AI Costs, Boosts Speed
Google's new TurboQuant technology dramatically reduces AI memory needs and boosts processing speed by up to 8x without losing accuracy. This breakthrough promises significant cost savings and expanded capabilities for AI applications.

Google Unveils TurboQuant: A Leap in AI Efficiency
Google has announced a significant breakthrough in artificial intelligence with its new TurboQuant technology. This innovative software dramatically reduces the memory needed for AI models and speeds up their performance, all without sacrificing accuracy. The development is so impactful that some analysts believe it could shake up the AI chip market.
Understanding AI Models and Memory
To grasp how TurboQuant works, it helps to understand how AI models, especially large language models (LLMs) like those behind chatbots, process information. These models learn by understanding the relationships between words in a sentence. For example, in the sentence “The animal didn’t cross the street because it was too tired,” the word “it” gains meaning from the words around it. The AI needs to remember these connections to understand context.
AI models store these connections in something called a KV cache. Think of it like a folder system. When the AI reads text, it creates a “key” (a label for the information) and a “value” (the actual data or meaning). This KV cache helps the AI quickly recall information without rereading everything. However, this cache can become very large, consuming significant memory and slowing down processing.
Google’s Polar Quant Approach
TurboQuant introduces a new method called PolarQuant. Traditionally, AI models use standard coordinates (like a map grid) to store data. This requires keeping track of multiple values for each piece of information. PolarQuant, however, converts this data into polar coordinates. Imagine giving directions not by saying “go three blocks east, then four blocks north,” but by saying “go five blocks in this specific direction (angle) and distance.” This method uses two pieces of information: the radius (how strong the data is) and the angle (its direction or meaning). This approach maps data onto a predictable grid, reducing the need for complex calculations and eliminating memory overhead.
The “angle” in PolarQuant is key. It represents the direction of the data’s meaning. When you understand this, Google’s own description of a “new angle on compression” becomes a clever pun. The AI’s ability to quickly access and understand these angles from its KV cache allows it to process information much faster.
TurboQuant’s Performance Boost
Google tested TurboQuant on various popular AI models, including Google’s own Gemma, Mistral, and Llama, running on powerful Nvidia H100 GPUs. The results were striking:
- 6x Reduction in KV Cache Memory: AI models now need six times less memory to store and retrieve information.
- 8x Speed Increase: The process of accessing this stored information is eight times faster.
- Zero Accuracy Loss: Crucially, these improvements come without any reduction in the AI’s ability to understand and generate accurate responses.
This is a significant departure from typical data compression, where reducing file size usually means losing some quality or detail. TurboQuant achieves efficiency without compromising the AI’s intelligence.
Why This Matters: Real-World Impact
The implications of TurboQuant are vast, particularly for businesses and developers running AI models at scale.
- Reduced Costs: Companies can expect up to a 50% reduction in costs for running AI models. This means cheaper API calls, more requests processed per second on existing hardware, and lower operational expenses.
- Larger Context Windows: The reduced memory requirements effectively increase the “context window” of AI models. This allows them to process much longer documents, understand more extensive codebases, or maintain longer conversation histories without hitting hardware limits.
- Enhanced Hardware Utilization: For companies like Google with their own hardware (TPUs) or those using Nvidia GPUs, TurboQuant acts as a multiplier. It means more AI models can run on the same hardware, or larger, more complex models can be deployed efficiently.
- No Retraining Needed: TurboQuant is a software update. It doesn’t require companies to retrain their existing AI models or fine-tune them, making implementation quick and easy.
Market Reactions and Future Outlook
Following the announcement, some memory chip stocks experienced significant drops, reflecting market concerns about decreased demand for memory chips. However, this reaction might be short-sighted. The principle of Jevons Paradox suggests that increased efficiency often leads to increased overall usage, not less. As AI becomes cheaper and faster, new and more demanding applications are likely to emerge, potentially driving demand for more powerful hardware in the long run.
Google’s decision to publish its findings, much like its earlier “Attention Is All You Need” paper that introduced the Transformer architecture, is seen as a significant contribution to the AI community. By sharing this technology, Google not only benefits from its own improved efficiency but also accelerates progress across the entire industry.
For end-users, this breakthrough means more capable AI applications, potentially with lower costs or increased accessibility. Companies that rely heavily on AI inference, from chatbots to complex analytical tools, stand to gain considerably. The technology is expected to make advanced AI more affordable and practical for a wider range of applications.
Source: Google's TurboQuant Crashed the AI Chip Market (YouTube)
Related Articles


OpenAI Renames Product Team to AGI Deployment
OpenAI has internally renamed its product team to "AGI Deployment," signaling a shift towards delivering advanced AI capabilities. This move comes as industry leaders like Jensen Huang and Mark Gubrad suggest AGI may have already been achieved, though definitions and timelines vary.
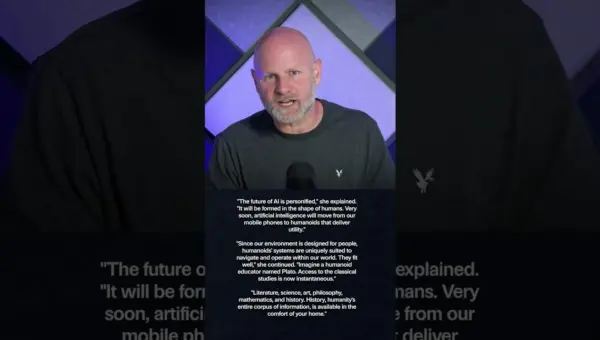
Melania Trump’s AI Summit: A Glimpse into Tech’s Future?
Former First Lady Melania Trump hosted an AI summit, discussing humanoid robots and instant access to information. Commentary highlighted that such information access has long been available via the internet, raising questions about technological communication.


Anthropic’s ‘Mythos’ AI Leaks, Sparking Security Fears
Anthropic's powerful new AI model, Claude Mythos, was accidentally leaked online, raising concerns about its advanced cybersecurity capabilities. While Anthropic emphasizes its role in helping defenders prepare for future AI threats, the leak has also sparked debate about its intentionality and impact on the cybersecurity market.